Physical migrations
Of all the techniques used during Data Centre Migrations physical hardware migrations, sometimes referred to as Lift & Shift (although this is less precise and subject to different interpretations), is considered by some to be one of the simplest. Just so we are clear let’s define what we mean by lift and shift. It is when servers and other associated equipment such as storage arrays are physically moved from one location to another. So the principle is very simple, but in fact it needs quite a lot of detailed planning to make sure such moves do not turn into a disaster. In my experience servers selected for this migration method will typically be part of a business service that can tolerate a reasonably extended service outage of say 2 to 5 days. Having said that I have seen failing Data Centre Migration projects consider this approach as an “acceleration” technique. That only stands a chance of flying if you are prepared to tolerate the implied extended outage.
A typical Lift & Shift migration scenario
We decide to move a physical Windows server. The high level plan is typically something like this
- Capture config details of the server
- Ensure that Space, Power and Network connections are in place in the target Data Centre
- Back up the server (Possibly a special “Migration” backup)
- Power it off
- Disconnect and de-rack it
- Ship to the Target Data Centre
- Re-rack it and remake all connections (maybe hold off on network connections)
- Boot the server
- Carry out any necessary re-configuration (e.g. change IP addresses)
- Connect to the network if we didn’t do so before
- Carry out some basic testing
- Put the server back into live service (if testing is successful)
Planning
Even though, conceptually, physical moves are simple a fair amount of planning is required to minimise the risk of failure. The first step is verifying that a server or servers are actually candidates for a physical migration. Organisations have many reasons for considering physical migration. One factor may be lack of budget to stand up an entire duplicate set of hardware in the target data centre. Another may be the need to migrate legacy systems for which there are no readily available on-line migration tools. An important step is to conduct frank discussions with the business application owners. There are some significant risks attached to a physical migration, mainly around potential service outages. Although the probability of many of these risks materialising are low the business needs to understand and buy into them. An example of this is say we have a plan to move a server over a weekend and that the move will consume most of the available time. If we can’t get that server up and running in the new environment we may decide to move it back to the old environment. That is probably going to take as much time as it took to move it in the first place. So a 2 day outage turns into 4 days or longer. This may not be an acceptable risk for a business critical system. You may say that it is unlikely that such legacy systems will be business critical. I have to say that I have encountered a surprising number of such systems that are, including one out of support system, where all the application support SMEs had left the company but which was responsible for bringing in over £20 Million of revenue annually. Another thing to consider is the possibility of total loss of one or more servers in transit. Granted the probability of this is very low but it is not zero. It is worth having at least an outline plan as to how you would deal with this. The plan itself may not involve significant, or indeed any, cost as such. For example you could locate a reseller who has the equipment in stock and negotiate an option to purchase which is good for say a week. Another alternative is to line up a provisional short term rental which would buy you some time if the worst happened. The key point is to have some idea as to how you would replace a server before it gets trashed and not after. If sourcing a replacement is going to be difficult or time consuming that needs to be factored into your planning and risk management. You should gather some information before you have a detailed discussion with the business. It is better to be able to put some numbers around worst case scenarios to help decide if the business can or can’t accept them. For example you might be able to say something like “In the event of a total toss of the system in transit we would be able to obtain a replacement in 2 days and expect to restore and recommission it in a further 2 days”.
Using a move partner
When I first started doing this stuff I was involved in a few DIY moves with rented trucks and the BAU IT team pitching in do the move. This was not just for small companies either, one move was for a major International Bank. These days, however, you are likely to want to involve a specialist computer moves partner. These organisations will have specialist equipment and vehicles to help minimise the risk. With their experience of such exercises they may also be able to help you with your planning. In passing some DC move companies offer a “dual vehicle” option at extra cost. This is where a second vehicle will shadow the primary move vehicle and be able to take on its load in the event of a breakdown. This reduces the risk somewhat, particularly for moves that have a tight schedule. However, it does not eliminate the risk of say the vehicle being involved in an accident. In these cases the Police may take control and may not allow you access to the vehicle for a prolonged period while they carry out crash investigation.
I have a reasonably comprehensive, but by no means exhaustive, check list at the end of this post that should help you get started with your planning and other phases of a move.
Preparation
To minimise the risk of failure there is a fair amount of preparation to be carried out in advance of the actual move. You need a detailed technical audit of the server or other equipment that you are going to move. This needs to come from information garnered from the current equipment set up itself and not from a CMDB. Why? Because sadly many CMDBs are not up-to-date or comprehensive enough. Yours may be the exception but there is no substitute for having definitive data.
You also need to make sure the server is not currently experiencing any issues or problems. Having someone scan the logs and report any issues to you is a good first step. By the way its a good idea to ask for email evidence of everything as part of “best practice”, even if this may make you appear to be distrusting. I recall on one DCM being sent a report from the BAU support team on several servers that were due for migration saying that they were working fine. I then asked if they could send me the info they had used to come up with that evaluation. Part of the evidence pack was a set of performance graphs from the corporate monitoring system, that on close inspection showed that 3 of the servers had been stuck at a 100% CPU utilisation for over a week!
One of the many other things you will need to get done is a “precautionary reboot” prior to the move. The reason for doing this is so that you can determine that the server will reboot without issue. It’s all too easy to have a server that hasn’t been rebooted for 3 months or longer with some, yet to be activated, patch or configuration change. As soon as you reboot these changes come into effect and there is a chance that they may kill the server or the apps running on it, nothing whatsoever to do with you migrating it but that is where the finger of blame will point if you fail to carry out a reboot test beforehand. Best to get these issues out of the way a week or two in advance of the actual move so there is sufficient time to remediate any issues. Once you have done this try to impose strict change control, if you can, to make sure nothing else creeps in in the intervening time between your reboot test and the actual move. This does not just apply to lift and shift migrations by the way, it is best practice for all server migrations.
Execution
Even though a physical migration may be carried out over several days it still needs tight planning with good communications management. All the parties involved need to know how to communicate that they have finished their piece, or in the worst case that they are having issues. As well as the team actively involved in the migration you will also probably need some key resources on call. Amongst these may be senior business managers who can provide input and decisions in the event of problem situations. All this needs a well-developed plan and confirmation that all involved know their roles, hand-off points and routes to escalation. Typically the migration project manager will be the focal point for all this. If the physical migration is part of a larger exercise there may be a 24×7 command centre with a permanently open conference call to report progress and issues.
What if it gets broken in transit?
I clearly remember many years ago moving a pedestal server system with wheels down in the elevator and then rolling it out towards the tail lift of a waiting truck. My colleague tripped on the sidewalk and the server escaped from us. We both watched in astonishment as it shot away from us travelling off to one side of the truck bumping violently over the kerb and into the road. Luckily no traffic hit it and once we had recovered it and installed it in the new location, to our immense surprise, it actually came up with no faults. Yes we were dumb to move it on its rollers and we should have palletised it. However, what this illustrates is that all sorts of things can go wrong during a physical move, such as the truck being involved in a crash, and in the worst case scenario you will lose the server or servers that it is carrying. As we have said your planning needs to address this risk by determining how you could replace the server. Another aspect of this that should go without saying is that you should have a backup of the server and all its data at the point in time it was decommissioned for the move and have the wherewithal to restore it at the new location. Check that there will be compatible tape systems to use to restore the server in the new site. Also your technical team should also have at least an outline plan as to how they would recover to non-identical hardware.
What if it fails to come up at the other end?
Computers don’t like being moved, and that’s a fact. Rolling a server onto and off a truck, even a special computer move rig, can jolt the system pretty badly. I have had servers where during a move some component or cable has become unseated just enough to stop the system from coming up at the other end. Don’t even ask me about the racked server that fell out of its harness while being hoisted up to the 5th floor. It worked by the way, but when we needed to upgrade it a year later we had to cut the rack to get it out as it had been fatally distorted by its fall. So there are two things you need to do. Firstly the location of the server needs to be updated on the contract with your maintenance provider. Secondly many maintenance providers consider a failure resulting from moving a server to be outside the scope of standard contracts. You need to find out how your maintenance provider handles this. If you are not covered, or if the server is only on Monday to Friday cover, you will probably need to arrange for some special maintenance cover to be on standby during the move weekend or evening.
Depending on when you do your move thermal stress and condensation are also factors that can cause issues, particularly if you are doing your move in the middle of winter (in a country where winter is cold!). If equipment has become very cold in transit to the new data centre it should be allowed to acclimatise for at least several hours before powering on so as to reduce the risk of thermal stress and condensation killing components. Of course this can be hard to allow for during a tightly scheduled weekend or overnight move. However, there is nothing to stop the server being installed in its rack and connections to it made whilst it is acclimatising so there will be some degree of timing overlap. This risk (and the mitigation actions) are significantly reduced and possibly eliminated if servers are packed in insulated transit cases for the move. This is not so easy if you are moving entire racks but these can be wrapped in polythene and bubble wrap which will provide some degree of insulation.
Plugging it all in
In the simplest case all you need to do is plug in a power cord and a network cable and you are good to go yes? Well maybe but most servers will have way more connections than that. So to try to make this run smoothly you need to have documented and ideally labelled all the connections in the source environment. The cabling in the target environment also needs to have been labelled and documented. Also the connections in the target environment need to have been tested wherever possible. It is not too difficult for a technician to wander around with a laptop plugging in to the server network cables (having set the laptop network port to the appropriate server address) and run a simple test such as pinging the router for that interface. Fibre channel, SCSI and other types of connection are not so easy to test in advance.
Can we connect to it to fix it?
You have avoided or overcome all the obstacles we have mentioned so far. The server appears to boot up OK but nobody can connect to it. How do you fix it? Many if not most servers these days are “headless”. That is to say they don’t have a keyboard and monitor attached. Obviously they will eventually be attached to whatever lights out management technology exists in the new data centre but there may be issues getting the server started up in its new home and it may not be easy to get the remote management technology to work straight away. So the re-install team may need to have a way to talk to the server before it is connected to the target data centre management infrastructure. This may be a Monitor & Keyboard, it may be a laptop with a serial connection (not usually available out of the box on today’s laptops) or some other solution. The important point here is the migration technical team need to know how to connect to the server “locally” and have any necessary technology on hand to enable them to do it. Many Data Centre operators have “crash carts” with a monitor a keyboard and possibly other cabling and sundries needed to speak to a relocated server. Make sure your migration technical team have access to such a facility and if there isn’t one, for example if you are migrating to a co-location Data Centre then put one together.
Aftermath
Issues may arise shortly after a system has been migrated. On some projects the DCM team provide a “Warranty period” during which they will rapidly make resources available to resolve any issues with the server. If you are going to do this you need to decide what the warranty period will be. You will also need to ensure that you retain enough resources to provide the necessary cover, particularly after the last migration wave. Another, fairly obvious, post migration activity is to run a “Lessons Learned” session and record the results. This is particularly important if there are still other physical migrations yet to be carried out. On big projects there may be multiple work streams so it is important that they have access to each other’s Lessons Learned material.
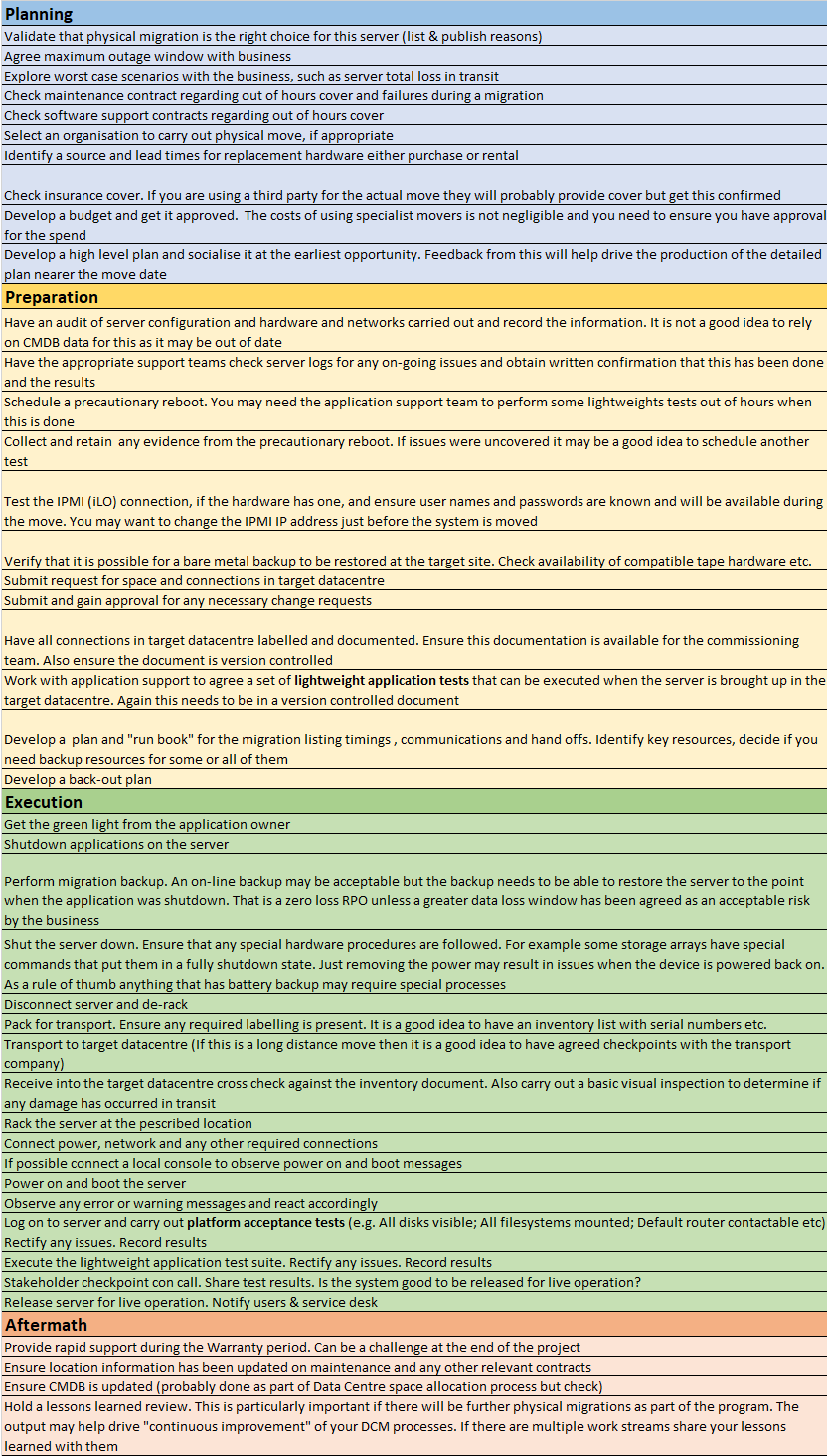
Checklist
Below you will find a simple, non-exhaustive checklist for the various phases of a physical relocation.